
微信扫码咨询
英特尔就第一时间优化并验证了80亿和700亿参数的Llama 3模型,凭借英特尔锐炫显卡的强大性能,开发者能够轻松在本地运行Llama 3模型,为生成式AI工作负载提供加速。
Meta此前已经发布了新一代Llama 3大语言模型,在发布后不久,英特尔就第一时间优化并验证了80亿和700亿参数的Llama 3模型在英特尔AI产品组合上的运行情况。在客户端领域,测试表明凭借英特尔锐炫显卡的强大性能,开发者能够轻松在本地运行Llama 3模型,为生成式AI工作负载提供加速。
此外,英特尔酷睿Ultra H系列处理器展现出了高于普通人阅读速度的输出生成性能,而这一结果主要得益于其内置的英特尔锐炫GPU,该GPU具有8个Xe核心,以及DP4a AI加速器和高达120 GB/s的系统内存带宽。
英特尔酷睿Ultra处理器和英特尔锐炫显卡在Llama 3模型发布的第一时间便提供了良好适配,这彰显了英特尔和Meta携手为本地AI开发和数百万设备的部署所作出的努力。英特尔客户端硬件性能的大幅提升得益于用于本地研发的PyTorch和英特尔PyTorch扩展包等丰富的软件框架与工具,以及用于模型部署和推理的OpenVINO工具包。

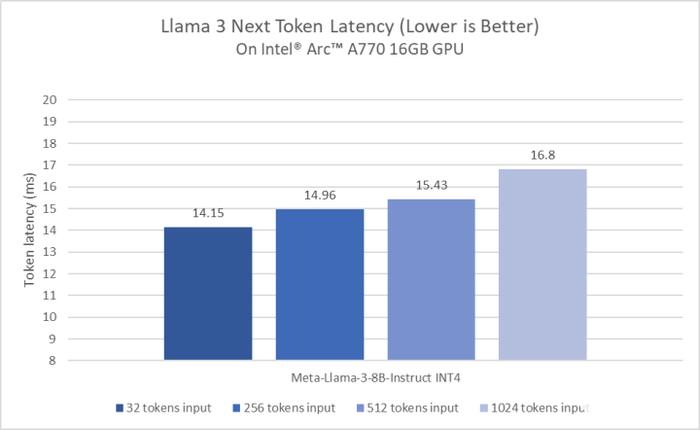
而根据具体的测试样例来看,在使用IPEX-LLM库运行70亿参数的Mistral模型时,锐炫A770 16GB显卡每秒可以处理70个token(TPS),比使用CUDA的GeForce RTX 4060 8GB的TPS高出70%。英特尔内部测试表明,锐炫A770 16GB显卡在运行大模型时能够提供卓越的性能。相比RTX 4060,锐炫A770 16GB显卡在运行大多数模型时具备极有竞争力或领先的性能,这也使其成为在本地运行大语言模型的更优选择。
 13560189272
13560189272  地址:广州市天河区黄埔大道西201号金泽大厦808室
地址:广州市天河区黄埔大道西201号金泽大厦808室 





























